
2023. 6. 6. 12:56ㆍAlgorithm
1. 특이한 정렬
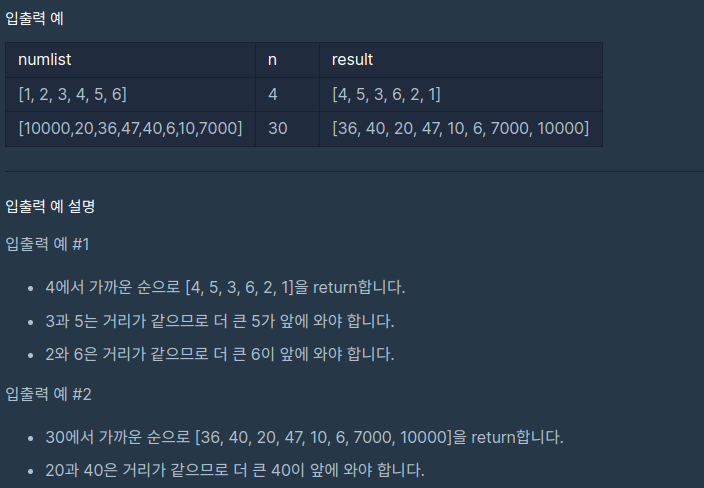
(문제 설명, 제한사항, 입출력 예)
배열 numlist와 정수 n이 주어질 때, numlist의 원소를 n으로부터 가까운 순서대로 정렬한 배열을 구하라는 문제이다.
만약 n으로부터 거리가 같다면, 더 큰 수를 앞에 오도록 배치하면 된다.
단, numlist 배열은 중복된 원소를 갖지 않는다.
n의 범위는 1 이상, 10,000 이하로 제한한다.

(내가 생각한 풀이 과정)
이 문제는 내가 처음 생각했던 것과 다르게 몇 번의 "도약"이 필요했던 문제였다.
처음 생각한 풀이 과정과 나의 도약을 함께 따라가면서 이해해 보자.
우선, 처음 생각한 풀이 과정은 간단했다.
n과 가까운 수를 구하기 위해 num에서 n을 빼 절댓값을 씌워준 후, 새로운 리스트 1에 추가하고, 값이 작은 순서대로 새로운 리스트 2에 정렬하고, 새로운 리스트 1과 리스트 2를 바탕으로 index() 함수를 이용해 최종 반환 리스트를 구해주는 시나리오였다.
여기서 생긴 첫 번째 문제와 도약.
"만약 n으로부터 거리가 같다면, 더 큰 수를 앞에 오도록 배치해야 한다."
즉, n이 4이고 배열 numlist에 3과 5라는 원소가 있다면, [4, 5, 3]의 순서대로 정렬을 해줘야 한다는 것이었다.
나의 원래 방식대로 num에서 n을 빼기만 하고 절댓값을 씌워주면, 3도 (3-4의 절댓값 1) 5도(5-4의 절댓값 1) 구분이 불가능하게 같은 값이 도출되었던 것이다.
이런 경우를 구분해 주기 위해 나는 num에서 n을 빼고 추가로 0.1을 더 빼주기로 했다.
그렇다면 3은 (3-4-0.1) 절댓값 1.1이, 5는 (5-4-0.1) 절댓값 0.9가 도출되어 더 큰 값이 더 가깝게 인식될 수 있었다.
(물론, 문제 안에 정수라는 조건이 있었기에 가능한 풀이였다.)
두 번째와 문제와 도약.
설명이 어려워 예시를 들어보겠다.
입력값이 [1, 2, 3, 4, 5, 6]이고 주어진 정수 n은 4일 때, 위의 도약을 바탕으로 구해진 chlist 리스트는 [3.1, 2.1, 1.1, 0.1, 0.9, 1.9]이다.
이제 이 리스트와 원래의 입력 리스트를 바탕으로 인덱스를 찾아 정렬해 주려고 했다.
사용한 코드는 answer.append(numlist[chlist.index(min(chlist))]) -> answer라는 새로운 리스트에 추가를 할 것인데, chlist의 최솟값의 chlist 상의 인덱스 위치를 numlist의 인덱스 위치에 맞춰 추가하라는 뜻
결국, 문제는 최솟값을 추가하는 코드다 보니까 중복되는 부분이 계속 발생했다.
이때는 numlist의 원소가 최대 10,000이라는 조건을 활용해 이미 삽입된 워소는 10001로 바꿔 중복되는 부분을 제거하며 해결했다.
사실, 내가 너무 어렵게 문제를 해결한 감이 있어
이 문제는 나중에 다시 한번 코드를 리팩토링하고 싶은 마음이 있다.
(코드)
💡 내 코드
def solution(numlist, n):
chlist = [abs(num-n-0.1) for num in numlist]
answer = []
for _ in range(len(chlist)):
answer.append(numlist[chlist.index(min(chlist))])
chlist[chlist.index(min(chlist))] = 10001
return answer
💡 다른 사람의 풀이 코드
주석 참조 ^__^
def solution(numlist, n):
# num -> (abs(n-num), -num)
numlist = [(abs(n-num), -num) for num in numlist]
# 첫 번째 요소를 기준으로 오름차순 정렬 and 두 번째 요소를 기준으로 내림차순 정렬
numlist.sort()
# 두 번쨰 요소만 반환
return [-num for _, num in numlist]
2. 등수 매기기
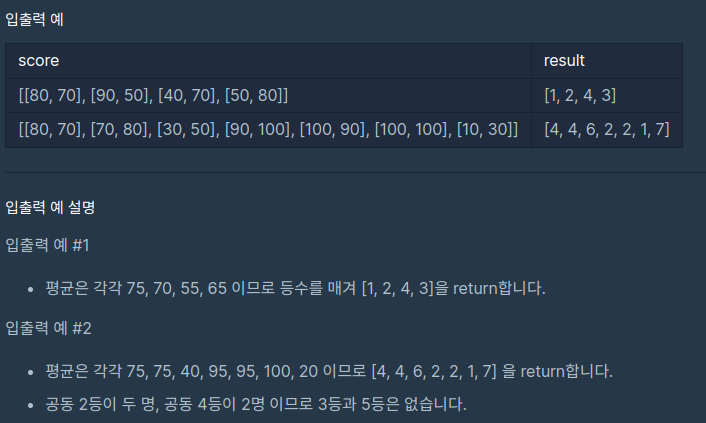
(문제 설명, 제한사항, 입출력 예)
영어 점수와 수학 점수가 순서대로 담겨있는 2차원 정수 배열(score)이 주어질 때, 영어 점수와 수학 점수의 평균을 기준으로 매긴 등수를 담은 배열을 구하라는 문제이다.
점수는 최저 0점부터 최고 100점까지 맞을 수 있으며, score 배열은 중복된 원소를 갖지 않는다고 한다.
단, 공동 순위는 존재한다.

(내가 생각한 풀이 과정)
우선 영어 점수와 수학 점수의 평균을 구해서 리스트(avg)에 담아주고, 점수 순위에 따라 내림차순으로 정렬을 한 별도의 리스트(sort_avg)를 또 따로 만든다.
별도의 리스트를 두 개 만드는 이유는 평균값을 담은 avg 리스트에 있는 값들을 하나씩 반복하면서 정렬되어 있는 sort_avg 리스트의 인덱스를 바탕으로 등수를 찾아줄 것이기 때문이다.
예시를 들어서 설명해 보겠다.
입력값은 [[80, 70], [70, 80], [30, 50], [90, 100], [100, 90], [100, 100], [10, 30]] 일 때,
평균을 구한 avg 리스트에는 [75, 75, 40, 95, 95, 100, 20]과 같이 담기게 되고,
평균값을 바탕으로 내림차순으로 정렬된 sort_avg 리스트에는 [100, 95, 95, 75, 75, 40, 20]과 같이 담기게 된다.
이제, avg 값을 하나씩 반복하면서 sort_avg 리스트 안의 인덱스를 바탕으로 등수를 찾아주자.
앗. 인덱스는 0부터 시작하고, 등수는 1등부터 시작하므로 인덱스의 수보다는 1을 더해줘야 한다는 점을 빼먹으면 안 된다.
75는 인덱스 3에 있으므로 4등, 뒤에 있는 75도 마찬가지 인덱스 3에 있으므로 4등, 40은 인덱스 5에 있으므로 6등.. 이런 식으로 쭉 구하면 올바른 등수를 구할 수 있다.
위의 예시처럼 공동 순위의 경우에도 파이썬에서의 index() 함수는 먼저 찾은 인덱스를 기준으로 앞의 값을 반환하기 때문에 조건에 관계없이 올바른 답을 반환한다는 것을 확인할 수 있다.
(코드)
💡 내 코드
def solution(score):
avg = [sum(num)/2 for num in score]
sort_avg = sorted(avg, reverse=True)
answer = []
for num in avg:
answer.append(sort_avg.index(num)+1)
return answer
💡 다른 사람의 풀이 코드
내 풀이 방법과 같지만, 마찬가지로 파이썬의 특성을 적극 활용해 코드를 3줄로 줄여버린 것을 볼 수 있다.
파이썬을 알고리즘에서 활용한다면, 아래와 같이 코드를 파이썬스럽게 쓰는 연습도 같이 해야 한다는 것을 느꼈다.
def solution(score):
a = sorted([sum(i) for i in score], reverse = True)
return [a.index(sum(i))+1 for i in score]
3. 옹알이 (1)
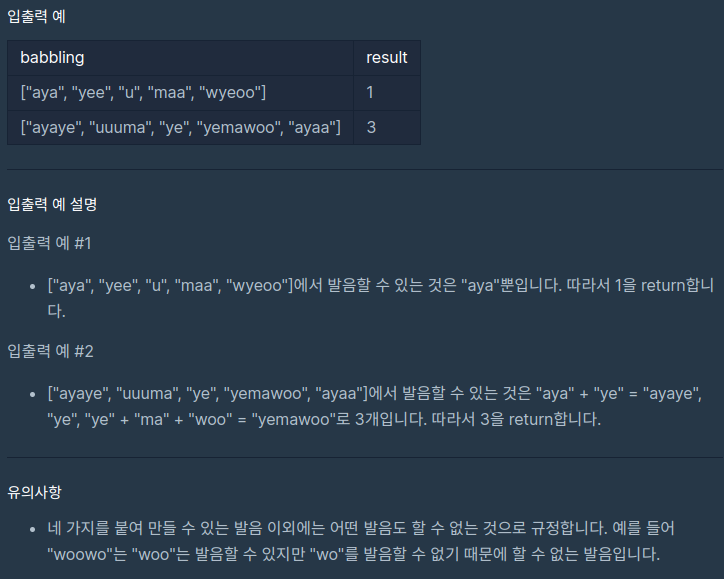
(문제 설명, 제한사항, 입출력 예)
아직 "aya", "ye", "woo", "ma" 네 가지 발음을 최대 한 번씩 사용해 조합한(이어 붙인) 발음밖에 하지 못하는 아기가 있다고 한다.
문자열이 담겨있는 babbling 배열이 주어질 때, 배열 안의 문자열 중 아기가 발음할 수 있는 단어의 개수를 구하라는 문제이다.
문자열은 알파벳 소문자로만 이루어져 있다.
또한, babbling의 각 문자열에서 "aya", "ye", "woo", "ma"는 각각 최대 한 번씩만 등장한다.

(내가 생각한 풀이 과정)
이번 문제는 나름 창의력(?)을 발휘해 재미있게 풀어봤다.
배열 속 문자열을 하나씩 확인해 줄 것이다.
어떻게 확인할 것이냐면, "aya", "ye", "woo", "ma"가 들어 있는지를 확인할 것이다.
그래서 만약 해당 문자들이 문자열 안에 들어있다면, 해당 문자("aya", "ye", "woo", "ma")를 "0"으로 바꿔줄 것이다.
전부 바꿔줬으면, 마지막에는 isdigit() 함수를 이용해서 문자열에 0만 남아 있는 경우에는 발음이 가능한 경우라고 판별할 수 있겠고, 다른 문자가 남아있다면 발음이 불가능한 경우라고 판단할 수 있을 것이다.
(코드)
💡 내 코드
def solution(babbling):
answer = 0
can_babbling = ["aya", "ye", "woo", "ma"]
for sp in babbling:
for can_sp in can_babbling:
sp = sp.replace(can_sp, "0")
if sp.isdigit(): answer += 1
return answer
4. 로그인 성공?
(문제 설명, 제한사항, 입출력 예)
사용자가 입력한 아이디와 패스워드가 담긴 배열 id_pw와 회원들의 정보가 담긴 2차원 배열 db가 주어질 때,
아래와 같이 로그인 성공, 실패에 따른 메시지를 반환하라는 문제이다.
- 아이디와 비밀번호가 모두 일치하는 회원정보가 있으면 "login"이라는 메시지를 반환한다.
- 로그인이 실패했을 때, 아이디가 일치하는 회원이 없다면 "fail"이라는 메시지를 반환한다.
- 로그인이 실패했을 때, 아이디는 일치하지만 비밀번호가 일치하는 회원이 없다면 "wrong pw"라는 메시지를 반환한다.
회원들의 아이디는 알파벳 소문자와 숫자로만 이루어져 있으며, 패스워드는 숫자로 구성된 문자열이다.
회원들의 비밀번호는 같을 수 있지만, 아이디는 같을 수 없다.


(내가 생각한 풀이 과정)
db 데이터를 반복하면서 입력된 id_pw의 아이디와 비밀번호 값이 일치하는 지를 비교하면 되는 비교적 간단한 문제이다.
id_pw의 0번째 원소 값은 아이디 값, 1번째 원소 값은 비밀번호 값이라는 점을 이용했고,
db를 반복하면서 체크할 원소(check)의 0번째 값도 마찬가지 아이디, 1번째 값은 비밀번호 값이라는 점을 이용했다.
즉, 직관적으로 비교해 주면 된다.
(코드)
💡 내 코드
def solution(id_pw, db):
for check in db:
if check[0] == id_pw[0]:
if check[1] == id_pw[1]: return "login"
else: return "wrong pw"
return "fail"